npm 很早就支持了 scope 功能,当前很多流行的库采用这种形式发布,如 babel:
{ "devDependencies": { "@babel/core": "^7.0.0", "@babel/plugin-proposal-class-properties": "^7.0.0", "@babel/plugin-proposal-object-rest-spread": "^7.0.0", "@babel/plugin-transform-runtime": "^7.0.0", "@babel/preset-env": "^7.0.0", "@babel/preset-react": "^7.0.0" }}scope 是一种很好的包管理方式。统一的“命名空间”,清晰、好辨识;在 registry 中使用统一的 organization 管理,不必担心命名冲突和冒用等。
在实际使用中,一个常见的场景是公司的私有仓库。使用统一的 scope 定义在私有仓库中定义私有包,绝对是一个非常好的方式。
指定 scope 从指定仓库安装
例如你所在公司的私有包全部使用 @xyz 这个 scope,仓库地址是 http://rnpm.xyz.com/。在实际的项目开发中,常常是即使用内部的私有包,也使用外部的开源包。最简单的区分方式就是定义 .npmrc :
@xyz:registry=http://rnpm.xyz.com/
可以定义在项目根目录,也可以定义在 $HOME 目录,仅仅是作用范围的区别。.npmrc 创建完成后,执行 npm install 时,scope 是 @xyz 的包都会从指定的仓库下载。
发布 scoped package
安装的问题其实很好处理的,即使不用上面提到的方案,直接定义 alias 也是可以的,如 cnpm 官方的文档提到的:
alias cnpm="npm --registry=https://registry.npm.taobao.org \--cache=$HOME/.npm/.cache/cnpm \--disturl=https://npm.taobao.org/dist \--userconfig=$HOME/.cnpmrc"
类似的你可以定义一个叫 xyznpm 的 alias,指向到 http://rnpm.xyz.com/ ,之后全部使用 xyznpm 代替 npm 即可。
大部分场景下这样也很好,但是如果遇到类似 lerna 这样基于 npm 的工具,就十分麻烦了。所以这里介绍另一种方式,npm 原生支持的多用户登录:
npm login --registry=http://rnpm.xyz.com/ --scope=@xyz
登录完成之后,执行 npm config ls 就可看到具体的 npm 设置:
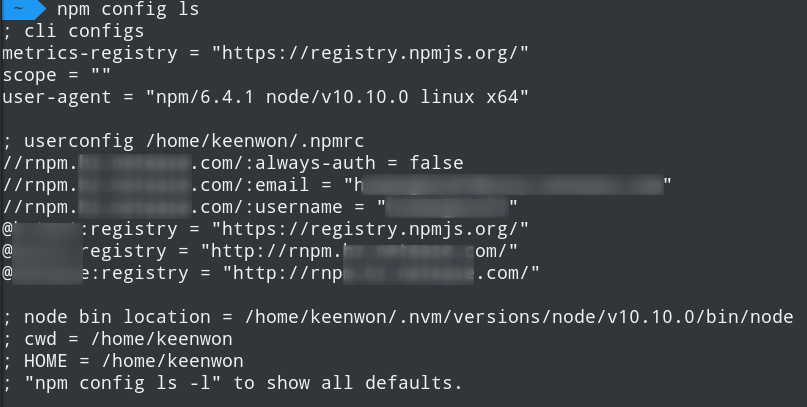
可以看到我设置了三个 scope,之后这三个 scope 下包在执行 npm install 和 npm publish 的时候,都会指向我配置的仓库。