本文通过一步一步的实践,带你探索Git内部工作原理。

Git 可能看起来像一个复杂的系统。如果上 Googl e搜索。Google 会自动弹出一些最常搜索的标题:
为什么 Git 这么难。。。
Git 就是太难了。。。
我们能够停止假装 Git 很简单、很容易学习吗。。。
为什么 Git 如此复杂。。。
乍一看,这些问题好像都是真的,但是你一旦理解了内部的概念,使用 Git 工作会变成一件愉悦的体验。Git 的问题是它非常灵活。所有灵活的系统的特点就是复杂。我强烈的认为解决其复杂性的唯一办法就是深入它提供的用户接口下面,理解内部的模型和架构。一旦你这么做了,就不会有什么魔力和非预期的结果。使用起这些复杂的工具得心应手。
不管是以前使用过 Git 还是刚开始使用这个神奇的版本控制工具的开发者,阅读了本文以后都会收获颇丰。如果你是应一名有经验的 GIT 使用者,你会更好的理解 checkout -> modify -> commit 这个过程。如果你刚开始使用 Git,本文将给你一个很好的开端。
在本文中我将使用一些底层的命令来展示 Git 内部是怎么工作的。你不需要记住这些命令,因为在常规的工作流中几乎不会使用这些命令,但是这些命令在解释 Git 内部架构时不可或缺。
本文比较长,我相信你会按照以下两种方式阅读:
快速从顶部滑底部,看一下本文的流程
跟着本文的练习完整阅读本文
通过练习你可以增强在这里获得的信息。
Git 是一个文件夹
当你在一个文件夹中执行 git init 命令时,Git 会创建 .git 目录。所以我们打开一个终端,创建一个新的目录并在这里初始化一个空的 git 仓库:
$ mkdir git-playground && cd git-playground$ git init Initialized empty Git repository in path/to/git-playground/.git/$ ls .git HEAD config description hooks info objects refs
这是 Git 存储所有 commit 和其他用于操作这些 commit 相关信息的地方。当你克隆一个仓库的时候就是复制这个目录到你的文件夹,为仓库里的每一个分支创建一个远程跟踪分支,并根据 HEAD 文件检出一个初始的分支。我们将在稍后讨论在 Git 架构中 HEAD 文件的用途,但是这里需要记住的就是克隆一个仓库本质上就是仅仅从别的地方复制一份 .git 目录。
Git 是一个数据库
Git 是一个简单的 key-value 数据仓库。你可以将数据存储到仓库中并获得一个键值,通过这个键值你可以访问存储的数据。将数据存储到数据库的命令是 hash-object,这个命令会返回一个40个字符的哈希校验和,这个校验和会被用作键值。这个命令会在 git 仓库中创建一个称为 blob 的对象。我们向数据库中写入一个简单的字符串 f1 content :
$ F1CONTENT_BLOB_HASH=$( \ echo 'f1 content' | git hash-object -w --stdin ) $ echo $F1CONTENT_BLOB_HASHa1deaae8f9ac984a5bfd0e8eecfbafaf4a90a3d0
如果你对 shell 不熟悉,上面这一段代码的主要命令是:
echo 'f1 content' | git hash-object -w --stdin
echo 命令输出 f1 content 字符串,通过管道操作符 | 我们将输出重定位到 git hash-object 命令。hash-object 的参数 -w 表示要存储这个对象;否则这个命令只是简单的告诉你键值是什么。 --stdin 告诉命令从 stdin 读取内容;如果不指定这一点, hash-object 希望最后输入一个文件路径。前面已经说到 git hash-object 命令会返回一个哈希值,我将这个值存储到 F1CONTENT_BLOB_HASH变量中。我们也可以将主命令和变量赋值像这样分开:
$ echo 'f1 content' | git hash-object -w --stdin a1deaae8f9ac984a5bfd0e8eecfbafaf4a90a3d0 $ F1CONTENT_BLOB_HASH=a1deaae8f9ac984a5bfd0e8eecfbafaf4a90a3d0
但是为了方便,我将在后面的代码中使用简短的版本为变量赋值。这些变量会在需要哈希字符串的地方使用,它和 $ 符号拼接起来作为一个变量读取存储的数据。
通过键值读取数据可以使用 带有 -p 选项的 cat-file 命令。这个命令需要接收带读取数据的哈希值:
如我前面所说, .git 是一个文件夹,并且所有存储的值/对象都放在这个文件夹中。所以我们可以浏览一下 .git/objects文件夹,你会看到 Git 创建了一个名称为 a1 的文件夹,这是哈希值的前两个字母:
$ ls .git/objects/ -l **a1/** info/ pack/
这就是 Git 存储对象的方式–每个 blob 一个文件夹。然而,Git 也可以将多个 blob 合并成一个文件生成一个 pack 文件,这些 pack 文件就存储在你前面看到的 pack 目录。Git 将这些 pack 对象相关的信息都存储到 info 目录。Git 基于 blob 的内容为每一个 blob 生成哈希值,所以存储在 Git 中的对象是不可修改的,因为修改内容就会改变哈希值。
我们往仓库中写入另外一个字符串 f2 content:
$ F2CONTENT_BLOB_HASH=$( \ **echo 'f2 content' | git hash-object -w --stdin )**
如你所预期的那样,你会看到 .git/objects/ 目录下现在有两条记录 9b/ 和 a1/ :
$ ls .git/objects/ -l **9b/** **a1/ ** info/ pack/
树(Tree)是一个内部组件
现在我们的仓库中有两个blob:
F1CONTENT_BLOB_HASH -> ‘f1 content’F2CONTENT_BLOB_HASH -> ‘f2 content'
我们需要一种方式来将他们组织到一起,并且将每一个 blob 和一个文件名关联起来。这就是 tree 的作用。我们可以按照下面的语法通过 git mktree 为从而每一个 blob/文件 关联创建一个树:
[file-mode object-type object-hash file-name]
关于文件的 file mode 可以参考这个答案提供的解释。我们将使用 100644 模式,这一模式下 blob 就是一个常规文件每一个用户都可以读写。当检出文件到工作目录时,Git 会根据 tree 实体将相应的文件/目录设置成这个模式。
所以,这样就可以将两个 blob 和两个文件建立关联:
$ INITIAL_TREE_HASH=$( \ printf '%s %s %s\t%s\n' \ 100644 blob $F1CONTENT_BLOB_HASH f1.txt \ 100644 blob $F2CONTENT_BLOB_HASH f2.txt | git mktree )
和 hash-object 一样,mktree 命令也会返回创建好的树对象的哈希值:
$ echo $INITIAL_TREE_HASHe05d9daa03229f7a7f6456d3d091d0e685e6a9db
所以,现在我们的仓库中有这样一个树:

运行这个命令之后,git 在仓库中创建了第三个 tree 类型的对象。我们一起来看看:
$ ls .git/objects -le0 <--- initial tree object (INITIAL_TREE_HASH)9b <--- 'f1 content' blob (F2CONTENT_BLOB_HASH)a1 <--- 'f2 content' blob (F2CONTENT_BLOB_HASH)
当使用 mktree 命令的时候,我们也可以指定另外一个树对象(而不是一个 blob)作为参数。新创建的树会和目录而不是一个常规文件关联。例如,下面的命令会根据一个 subtree 创建一个和 nested-folder 目录关联的树:
printf ‘%s %s %s\t%s\n’ 040000 tree e05d9da nested-folder | git mktree
文件模式 040000 表明是一个目录,并且我们使用的类型 tree 而不是 blob。这就是 git 在项目结构中存储嵌套目录的方式。
Index 是安装树的地方
每一个使用 GIT 工作的人都应该很熟悉 index 或者 staging 区这两个概念,并且可能看到过这张图片:
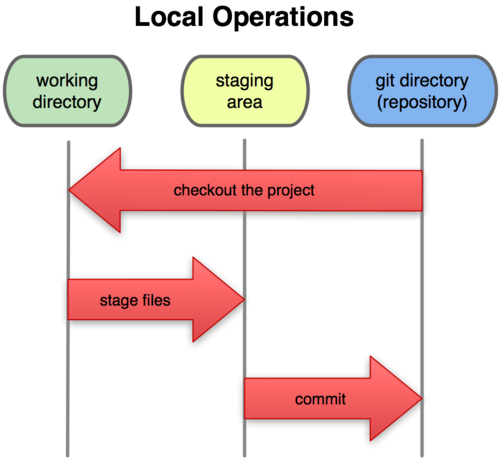
在右侧你可以看到 git repository,它用于存储 git 对象:blobs,trees,commits 和 tags。我们已经使用 hash-object 和 mktee 命令直接向仓库中添加了两个 blob 和一个树对象到仓库中。左侧的工作目录是你本地的文件系统(目录),也就是你检出所有项目文件的地方。中间这个区域我们称为 index 文件或者简称 index。它是一个二进制文件(通常存储在 .git/index),类似于树对象的结构。它持有一个排序好的文件路径列表,每一个文件路径都有权限以及 blob/tree 对象的 SHA1 值。
在这个地方,git 在作如下操作之前准备一个树:
将一个树写入仓库,或者
将一个树检出到工作目录
现在我们的仓库中已经有一个在上一章节创建的树。我们现在可以使用 read-tree 命令将这个树从仓库中读取到 index 文件:
$ git read-tree $INITIAL_TREE_HASH
所以现在我们期望 index 文件中有两个文件。我们可以使用 git ls-files -s 命令来检查当前 index 文件的结构:
$ git ls-files -s100644 a1deaae8f9ac984a5bfd0e8eecfbafaf4a90a3d0 0 f1.txt100644 9b96e21cb748285ebec53daec4afb2bdcb9a360a 0 f2.txt
由于我们还没有对 index 文件做任何修改,它和我们用于生成index文件的树完全一致。一旦我们在 index 文件中有了正确的结构,我们就可以通过带有 -a 选项的 checkout-index 命令将它检出到工作目录:
$ git checkout-index -a$ ls f1.txt f2.txt$ cat f1.txt f1 content$ cat f2.txt f2 content
对的!我们已经将没使用任何 commit 就添加到 git 仓库中的内容检出了。是不是很酷?

但是 index 文件并非总是停留在初始树的状态。你可能知道它可以通过这些命令改变,git add [file path] 和 git rm --cached [file path] 处理单个文件,git add .&nbs