参考文档 elasticsearch文档操作
上篇文章向读者介绍了Elasticsearch中修改数据的操作,使用了Elasticsearch提供的一整套强大的REST API,本文继续来看通过这一套API如何完成文档的基本操作。
本文是Elasticsearch系列的第四篇,阅读前面的文章,有助于更好的理解本文:
1.elasticsearch安装与配置 2.初识elasticsearch中的REST接口 3.elasticsearch修改数据
加载样本数据
为了完成后面的操作,我们首先需要一些样本数据,这个样本数据可以在http://www.json-generator.com/网站上自动生成,也可以直接下载已经生成好的,下载地址https://github.com/elastic/elasticsearch/blob/master/docs/src/test/resources/accounts.json?raw=true。
将下载下来的JSON数据放到当前用户目录下,然后执行如下命令,将数据导入到Elasticsearch中,如下:
curl -H "Content-Type: application/json" -XPOST "localhost:9200/bank/_doc/_bulk?pretty&refresh" --data-binary "@accounts.json"
小贴士:
这里实际上就是使用了上文提到的批量操作,只不过数据变为了一个本地的JSON文件而已。
注意,上面这行命令在执行过程中,可能会报如下错误:
The bulk request must be terminated by a newline [\n]
这是因为下载的accounts.json文件少了一个换行符,在下载的accounts.json文件最末尾,按下一个回车即可。
上面的命令执行完后,可以通过如下命令查看数据是否导入成功:
curl "localhost:9200/_cat/indices?v"
查看结果如下:

可以看到,成功的添加了1000个文档到bank索引中。
搜索API
整体来说,搜索条件既可以放在URL中,也可以放在REST请求体中,一般来说建议采用第二种方案,但是为了知识的完整性,这里对两种方案都予以介绍。
搜索条件在地址栏中
请求如下:
curl -X GET "localhost:9200/bank/_search?q=*&sort=account_number:desc&pretty"
请求解释:
q=* 表示搜索所有文档。
sort=accountnumber:desc表示请求结果按照accountnumber字段的值倒叙排序。
pretty则表示将响应的JSON格式化,方便阅读。
执行结果如下(部分):
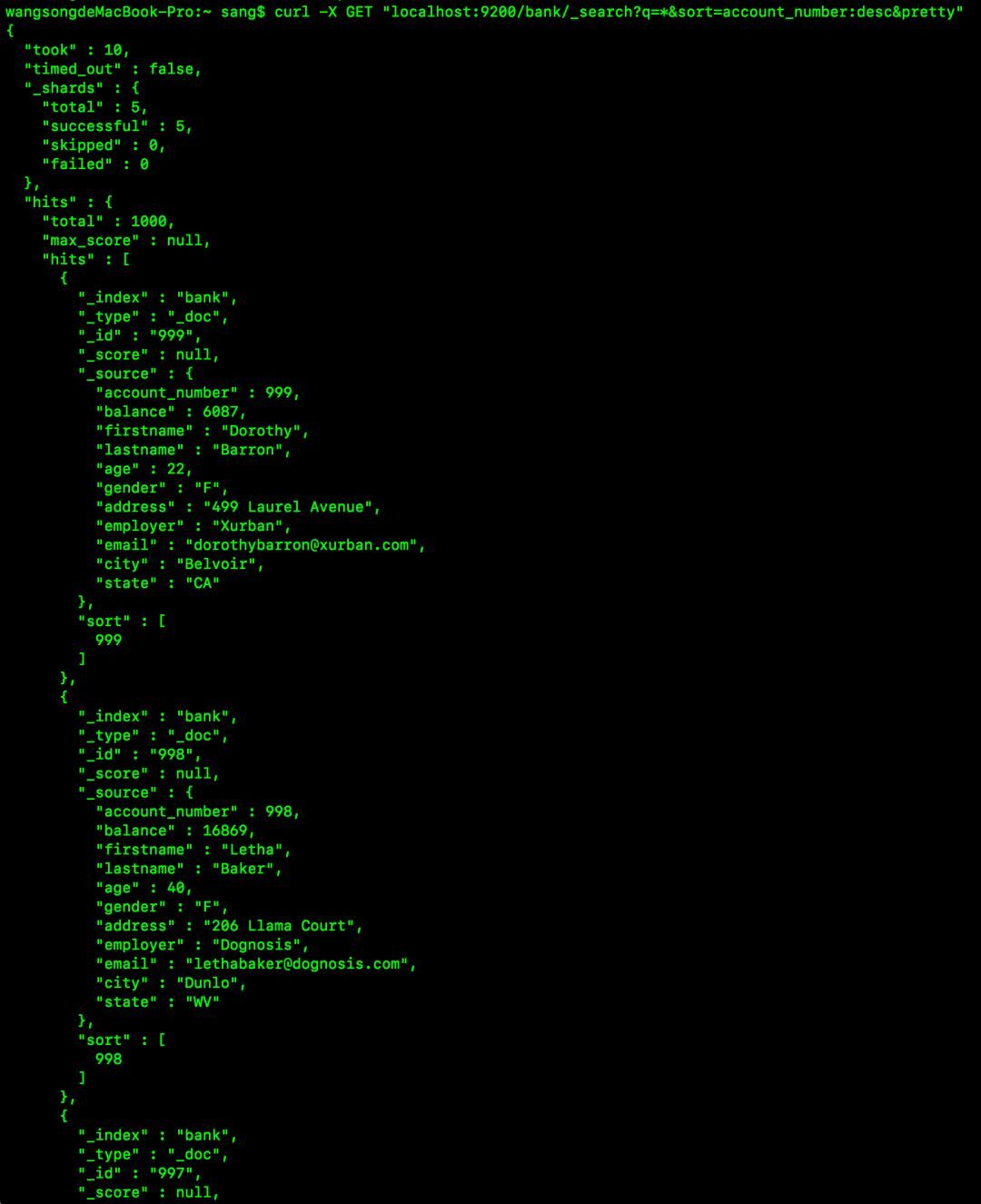
响应字段解释:
took表示搜索耗时,单位为毫秒。
timed_out表示搜索是否超时。
_shards表示有多少个分片被搜索了,成功搜索的分片数量、跳过的分片数量以及失败的分片数量。
hits表示搜索结果。
hits.total表示搜索到的文档总数量。
hits.hits表示搜索到的文档数组,默认显示搜索到的前十个文档。
搜索条件在REST请求体中
上面介绍的这种搜索条件在URL中,搜索条件也可以放在REST请求体中,下面这个请求等同于上面的请求:
curl -X GET "localhost:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d'{
"query": { "match_all": {} },
"sort": [
{ "account_number": "desc" }
]}'这里通过一个JSON请求体来描述查询条件,接下来向读者详细介绍这个JSON格式的查询条件。
查询语言介绍
Elasticsearch提供了一套JSON风格的查询条件格式,这称为DSL。DSL非常全面,虽然看起来可能有点难以理解,不过我们可以先从几个简单的案例来开始这个东西的学习。
回顾我们上文的查询条件:
curl -X GET "localhost:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d'{
"query": { "match_all": {} },
"sort": [
{ "account_number": "desc" }
]}'在上面这个请求中, query表示查询的定义, match_all表示查询指定索引下的所有文档。 sort则是一个排序字段,表示根据 account_number字段的值降序排列。
除了这些参数外,我们还可以指定返回的文档个数:
curl -X GET "localhost:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d'{
"query": { "match_all": {} },
"sort": [
{ "account_number": "desc" }
],
"size": 1}'这个表示返回的文档个数为1,执行结果如下:
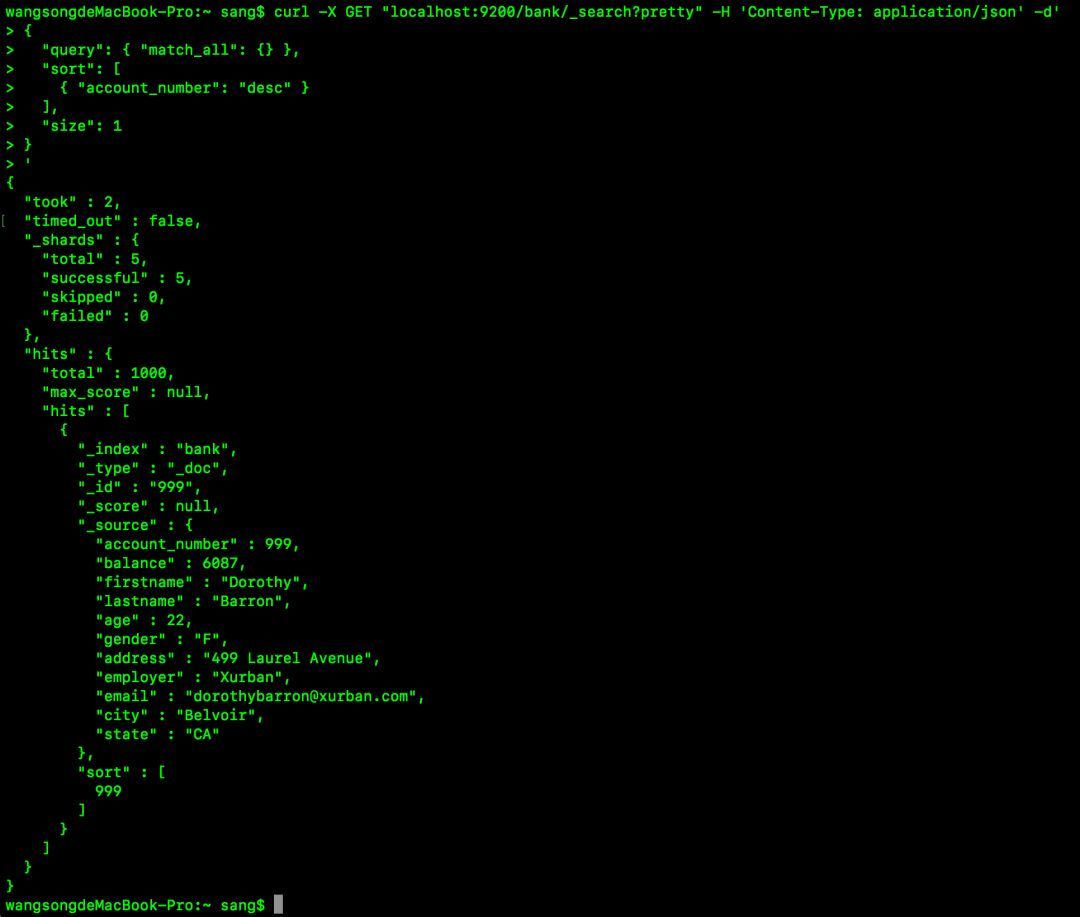
此时就只返回了一个文档,如果不指定的话,size默认为10。
也可以指定从第几个文档开始查询,类似于SQL中的分页,如下:
curl -X GET "localhost:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d'{
"query": { "match_all": {} },
"sort": [
{ "account_number": "desc" }
],
"size": 1,
"from": 10}'这个表示从第10个开始查询,查询1一个出来,如下:
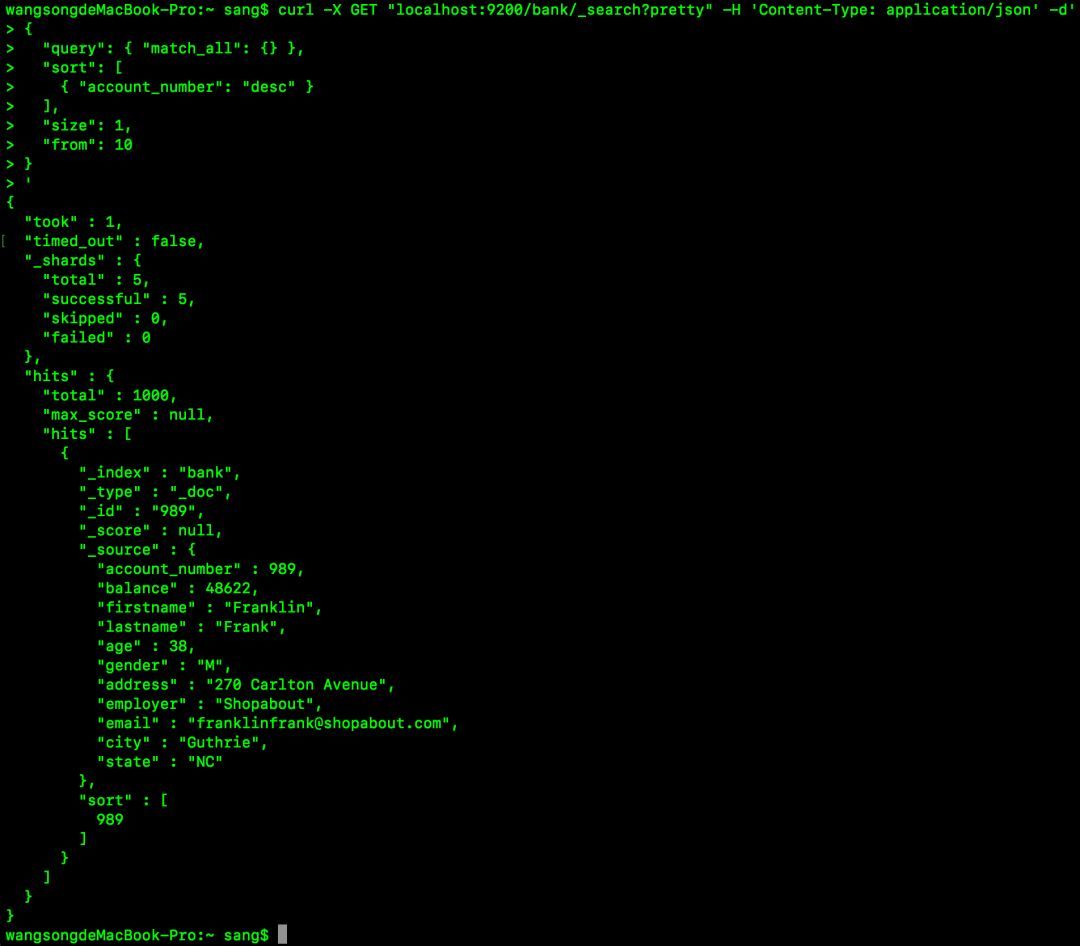
如果不指定from,则默认值为0。
执行搜索
通过上面一小节,读者对基本的查询已经有所了解,接下来再来看看查询中其他的一些细节。
自定义返回字段
默认情况下,查询结果中会返回查询文档的所有字段,如果不需要返回所有字段,则可以自定义返回字段,如下:
curl -X GET "localhost:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d'{
"query": { "match_all": {} },
"sort": [
{ "account_number": "desc" }
],
"size": 2,
"from": 10,
"_source": ["account_number","balance"]}'此时执行结果如下:
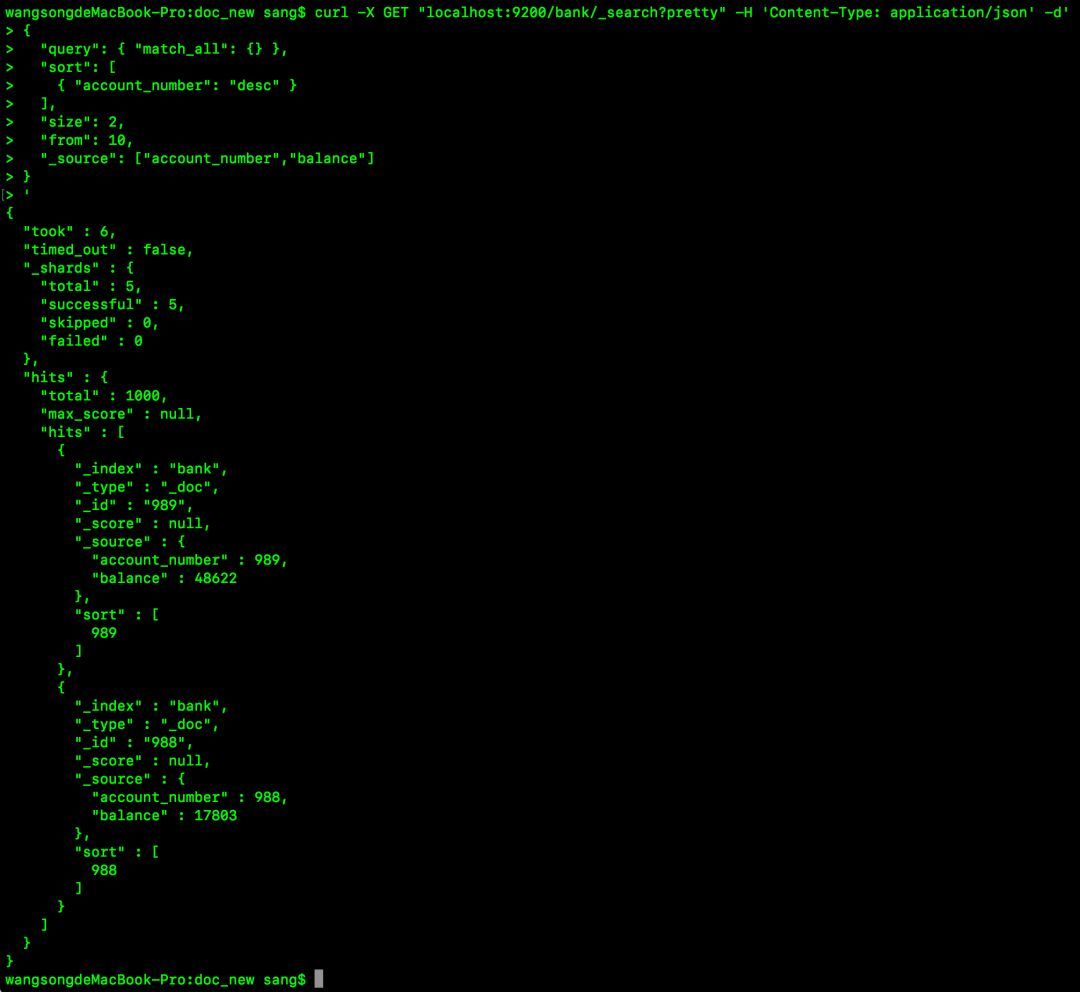
可以看到,查询结果中的 _source字段中的值已经发生了变化。
match
前面我们已经用过 match_all表示查询指定索引下的所有文档,我们也可以使用 match来指定查询条件,如下:
curl -X GET "localhost:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d'{
"query": { "match": { "account_number": 20 } }}'这个表示查询 account_number的值为20的文档。
his example returns all accounts containing the term "mill" in the address:
下面这个表示查询address中包含词语(term)“mill”的所有账户:
curl -X GET "localhost:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d'{
"query": { "match": { "address": "mill" } }}'如下则表示查询address中包含词语(term)“mill”或者“lane”的所有账户:
curl -X GET "localhost:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d'{
"query": { "match": { "address": "mill lane" } }}'match_phrase
match_phrase表示短语查询,如下查询表示查询address中包含“mill lane”的所有文档,如下:
curl -X GET "localhost:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d'{
"query": { "match_phrase": { "address": "mill lane" } }}'bool查询
bool查询允许用户将几个较小的查询条件,通过bool中的逻辑运算,组合成一个较大的查询条件,如下查询表示查询address中包含“mill”和“lane”的所有文档:
curl -X GET "localhost:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d'{
"query": {
"bool": {
"must": [
{ "match": { "address": "mill" } },
{ "match": { "address": "lane" } }
]
}
}}'上面案例中的must相当于and,而下面的should则相当于or(即查询的文档,只要包含的两个条件中一个符合,则该文档会被认为是符合条件的),如下:
curl -X GET "localhost:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d'{
"query": {
"bool": {
"should": [
{ "match": { "address": "mill" } },
{ "match": { "address": "lane" } }
]
}
}}'如下查询则表示查询address中既不包含“mill”,又不包含“lane”的所有文档,如下:
curl -X GET "localhost:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d'{
"query": {
"bool": {
"must_not": [
{ "match": { "address": "mill" } },
{ "match": { "address": "lane" } }
]
}
}}'也可以在一个查询中一起使用must、must_not、should,如下查询表示查询age为40,并且state不为ID的所有账户:
curl -X GET "localhost:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d'{
"query": {
"bool": {
"must": [
{ "match": { "age": "40" } }
],
"must_not": [
{ "match": { "state": "ID" } }
]
}
}}'执行过滤器
在前面的小节中,我们跳过了搜索结果中的_score字段,这个字段用来描述搜索结果的匹配度,得分越高,文档匹配度越高,得分越低,文档的匹配度越低。在Elasticsearch中,所有的查询操作都会触发匹配度得分的计算,但是并非所有的查询都需要获取匹配度这个参数,对于那些我们不需要匹配度得分的搜索中(例如仅仅只是想过滤文档集),可以使用Elasticsearch提供的另一种查询功能---过滤器。过滤器在概念上类似于查询,但是执行速度高于查询,之所以查询速度高,有如下两个原因:
过滤器不会计算相关度的得分
过滤器可以被缓存到内存中,在重复搜索时,速度会比较快
如下案例表示查询账户余额介于[20000,30000]之间的所有账户(查询条件和过滤条件也都可以自己定义):
curl -X GET "localhost:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d'{
"query": {
"bool": {
"must": { "match_all": {} },
"filter": {
"range": {
"balance": {
"gte": 20000,
"lte": 30000
}
}
}
}
}}'在查询时,究竟是使用过滤器还是使用查询,要考虑是否关注结果中的 _score字段。
执行聚合
聚合操作有点类似于我们在SQL中的聚合函数,开发者可以通过聚合操作,在一个查询结果中同时返回查询到的数据和聚合之后的结果,例如,按照state中的关键字对用户进行分组,然后按照分组后state的关键字数量进行排序,并展示出排名最高的前十个,如下:
curl -X GET "localhost:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d'{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword"
}
}
}}'这样的查询,有点类似于如下SQL:
SELECT state, COUNT(*) FROM bank GROUP BY state ORDER BY COUNT(*) DESC LIMIT 10;
请求执行结果如下:
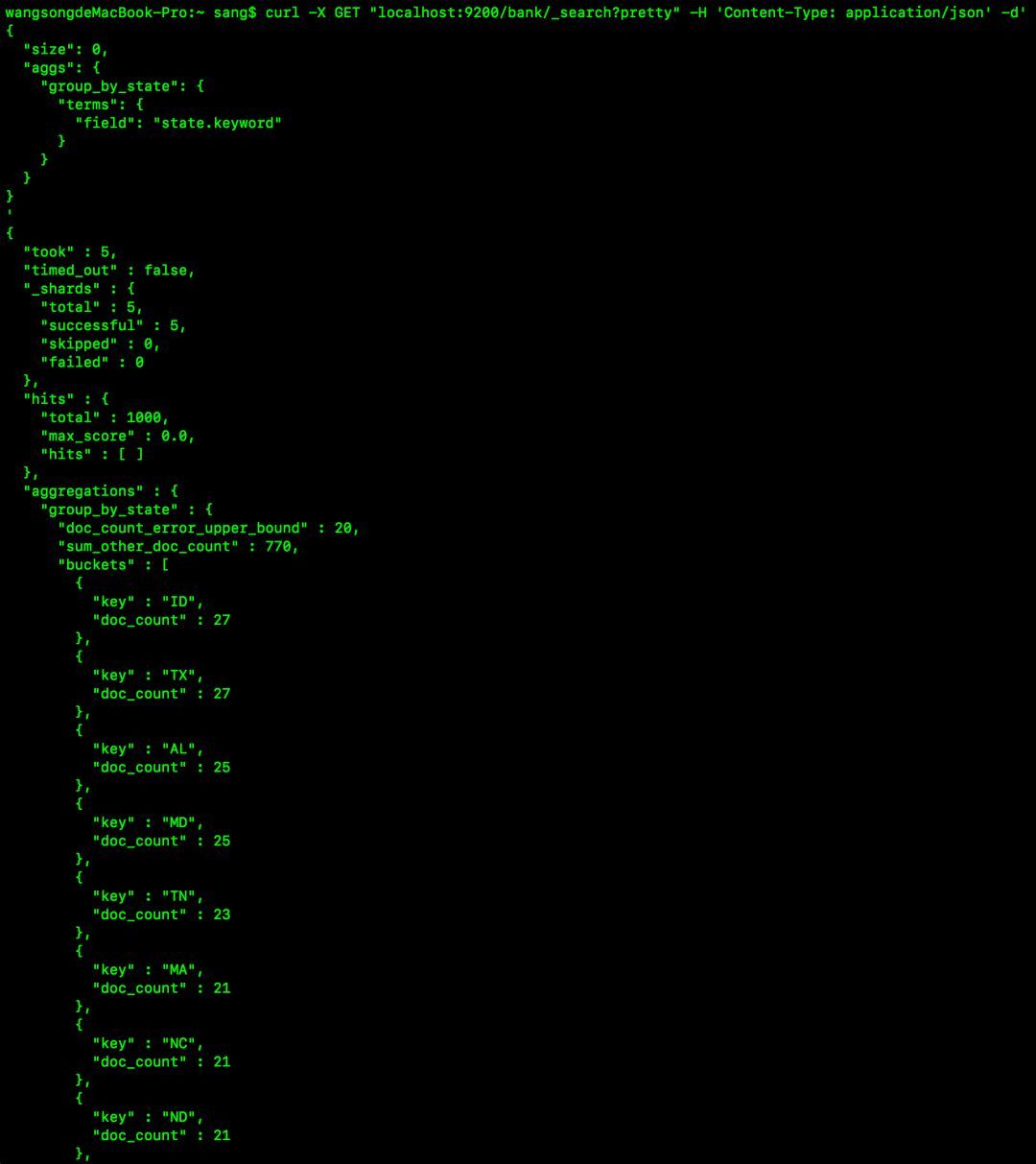
注意,在这个查询中,因为我们将size设置为0,因此只能看到聚合的结果,而没有查询结果。
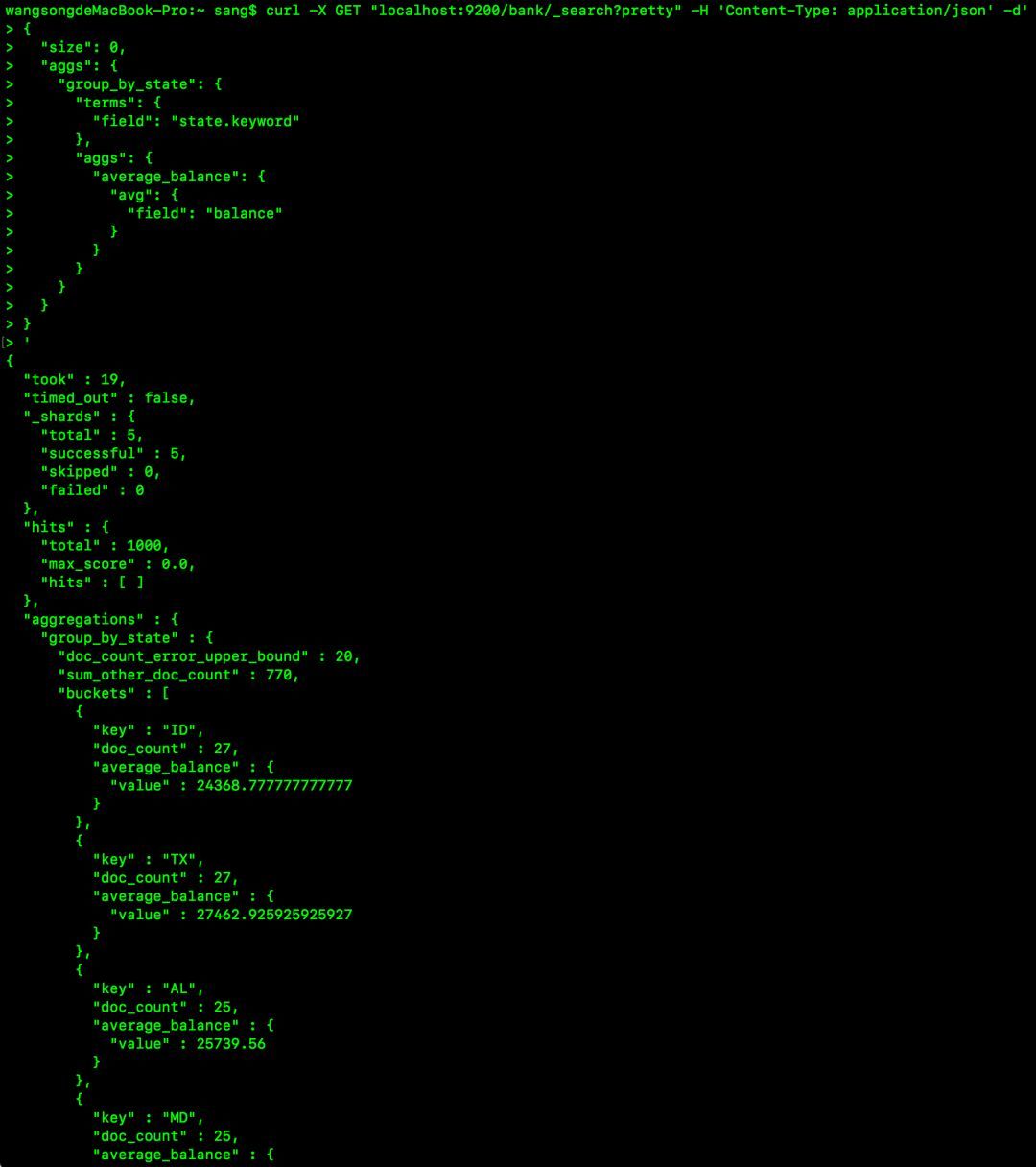
另外,这种聚合操作还可以互相嵌套,如下表示计算每个state账户的平均存款并列出前10个:
curl -X GET "localhost:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d'{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword"
},
"aggs": {
"average_balance": {
"avg": {
"field": "balance"
}
}
}
}
}}'
还可以按照平均余额进行排序,如下:
curl -X GET "localhost:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d'{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword",
"order": {
"average_balance": "desc"
}
},
"aggs": {
"average_balance": {
"avg": {
"field": "balance"
}
}
}
}
}}'如下请求则表示使用首先使用年龄段进行分组 (ages 20-29, 30-39, and 40-49),然后在此基础上再使用性别进行分组,最后再计算不同年龄段的不同性别用户的账户余额平均数:
curl -X GET "localhost:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d'{
"size": 0,
"aggs": {
"group_by_age": {
"range": {
"field": "age",
"ranges": [
{
"from": 20,
"to": 30
},
{
"from": 30,
"to": 40
},
{
"from": 40,
"to": 50
}
]
},
"aggs": {
"group_by_gender": {
"terms": {
"field": "gender.keyword"
},
"aggs": {
"average_balance": {
"avg": {
"field": "balance"
}
}
}
}
}
}
}}'